




1. Exploration de la série
La première étape consiste à visualiser la série dans le temps et à examiner les courbes d’autocorrélation (ACF) et d’autocorrélation partielle (PACF). Cette phase exploratoire permet :
- d’obtenir une première idée de la structure temporelle du phénomène étudié (tendance, cycles, fluctuations aléatoires) ;
- d’orienter le choix du type de modèle à ajuster, comme AR(1), MA(1), ARMA(1,1), etc. ;
- de repérer les signes de non-stationnarité.
Un ACF qui décroît très lentement, comme dans les graphiques précédents, indique généralement un besoin de différenciation. Comme le modèle généré est un modèle ARIMA(2,1,2), on peut donc dériver une seule fois. Les graphiques suivants sont obtenus après une différenciation :
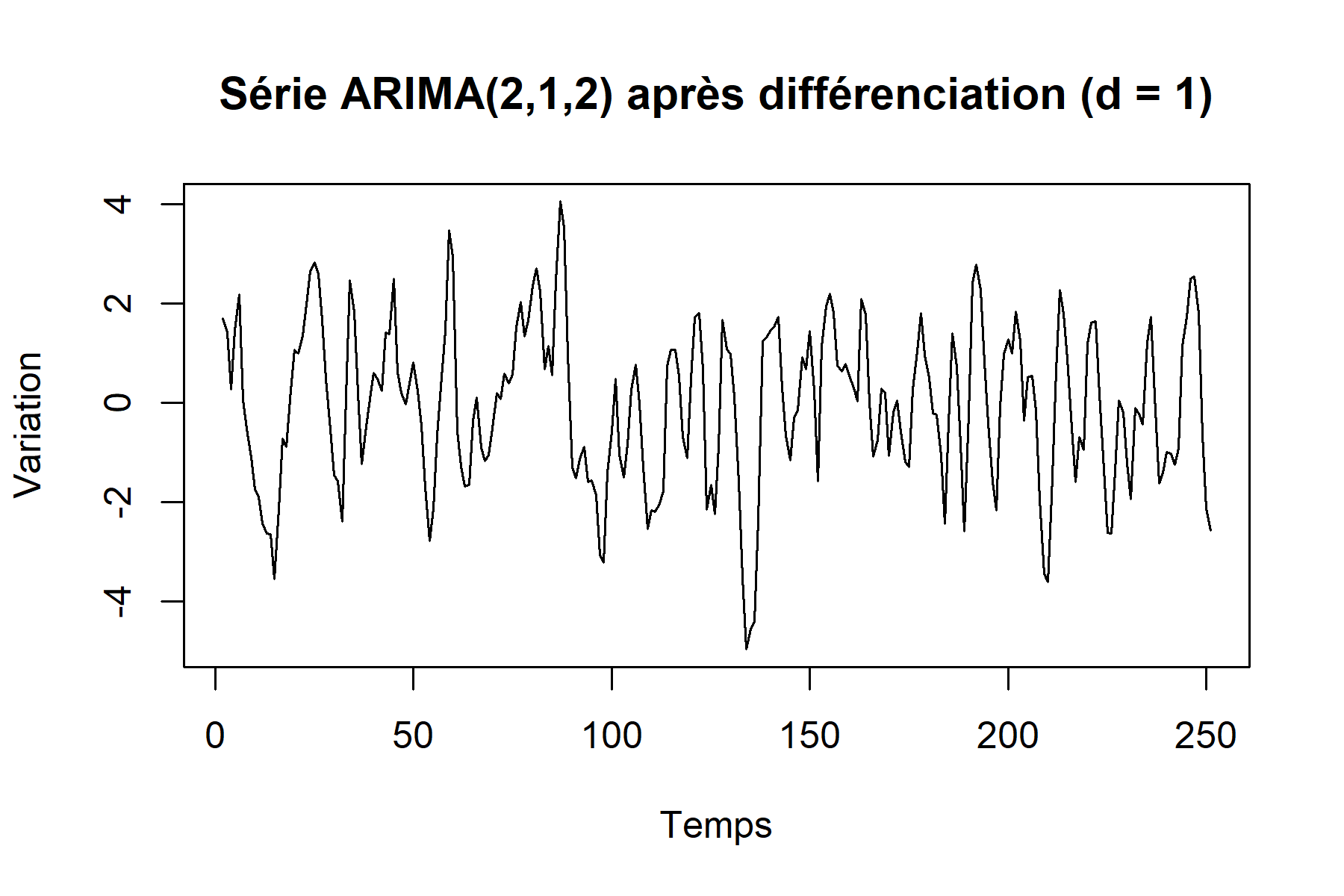
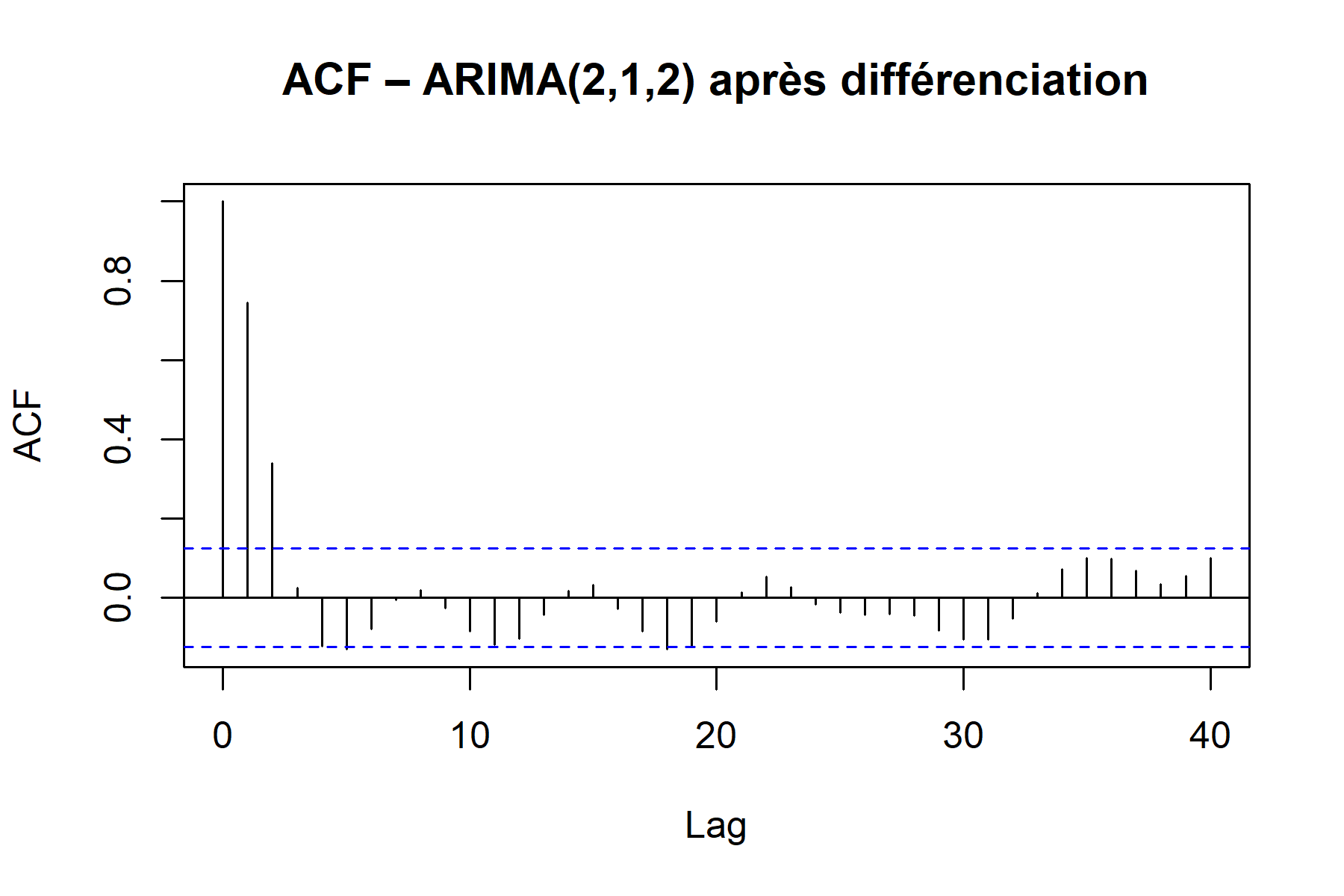
On effectue ensuite des tests de stationnarité (ADF, KPSS) pour déterminer si une différenciation est nécessaire et, si oui, en évaluer l’ordre \(d\).
2. Estimation des paramètres
Par la suite, plusieurs modèles candidats peuvent être testés, tels que ARMA(1,1), ARIMA(1,1,0) ou ARIMA(1,1,1).
Les coefficients \(\phi_i\) (effet autorégressif) et \(\theta_j\) (effet de moyenne mobile) sont ensuite estimés à partir des données (généralement par maximum de vraisemblance).
L’objectif est d’obtenir un modèle qui décrit fidèlement la dépendance temporelle tout en restant simple à interpréter.
En pratique, il est préférable de dériver la série autant de fois que nécessaire, puis d’estimer les coefficients d’un modèle ARMA. La librairie forecast ![]() du logiciel R gère automatiquement la différenciation, il n’est donc pas nécessaire de dériver avant la modélisation.
du logiciel R gère automatiquement la différenciation, il n’est donc pas nécessaire de dériver avant la modélisation.
3. Validation et sélection du meilleur modèle
Après ajustement, on vérifie la stationnarité des résidus : ils doivent se comporter comme un bruit blanc (autrement dit, ne présenter aucune structure temporelle résiduelle).
Les modèles sont ensuite comparés à l’aide de critères d’information, comme AIC (Akaike Information Criterion) et BIC (Bayesian Information Criterion) ![]() . Plus la valeur de l’AIC est faible, meilleur est le compromis entre la qualité d’ajustement et la simplicité du modèle.
. Plus la valeur de l’AIC est faible, meilleur est le compromis entre la qualité d’ajustement et la simplicité du modèle.
Remarque
Dans le logiciel R, ces étapes peuvent être automatisées grâce à la fonction auto.arima() de la librairie forecast ![]() . Cette fonction explore automatiquement différentes combinaisons de paramètres et sélectionne le modèle optimal selon les critères AIC et BIC. Elle permet également d’estimer µ (appelé drift dans ce cas).
. Cette fonction explore automatiquement différentes combinaisons de paramètres et sélectionne le modèle optimal selon les critères AIC et BIC. Elle permet également d’estimer µ (appelé drift dans ce cas).
Le code R complet de cette démonstration est disponible dans la section Code R du site.
Un exemple pratique
Dans leur étude menée à Wuhan (Chine), He et Tao (2018) ![]() ont appliqué des modèles ARIMA pour prédire le taux de positivité du virus de l’influenza chez les enfants sur une période de neuf ans (de 2007 à 2015).
ont appliqué des modèles ARIMA pour prédire le taux de positivité du virus de l’influenza chez les enfants sur une période de neuf ans (de 2007 à 2015).
Les données provenaient d’un réseau de surveillance sentinelle regroupant deux hôpitaux pédiatriques, avec un suivi hebdomadaire des échantillons testés.
Les auteurs ont montré que :
- les séries brutes de taux de positivité n’étaient pas stationnaires, en raison de tendances et de cycles saisonniers marqués ;
- après différenciation \((d = 1)\), la série devenait stationnaire, permettant d’ajuster des modèles ARIMA fiables ;
- certains sous-types viraux, comme A(H1N1)pdm09, pouvaient être modélisés efficacement par un ARIMA(0,0,1), décrivant des fluctuations à court terme sans tendance marquée ni effet saisonnier explicite.
Ces résultats démontrent la capacité du modèle ARIMA à décomposer la structure temporelle d’une série épidémiologique et à produire des prévisions plus fiables à court terme.
Cette étude illustre l’importance de la différenciation et de la sélection rigoureuse des paramètres afin d’obtenir des modèles fiables et interprétables dans la surveillance épidémiologique.