




Les modèles ARMA décrivent efficacement les dépendances temporelles d’une série stationnaire. En pratique, cependant, la plupart des séries épidémiologiques ne sont pas stationnaires : elles présentent des tendances à long terme (hausse ou baisse des cas) et des fluctuations cycliques.
Pour modéliser correctement ces séries et produire des prévisions fiables, il faut d’abord les rendre stationnaires. C’est précisément le rôle des modèles ARIMA (AutoRegressive Integrated Moving Average), qui prolongent la logique des modèles ARMA en y ajoutant une étape clé : la différenciation.
Le principe de la différenciation
La différenciation consiste à soustraire à chaque observation la valeur précédente. Cela permet de supprimer les tendances linéaires et de stabiliser la moyenne de la série, ce qui la rapproche d’un processus stationnaire. Sous forme d’équation, ça donne ceci :
$$\nabla y_t = y_t – y_{t-1}$$
Cette transformation correspond au calcul des variations d’une unité temporelle à une autre. Si la série n’est toujours pas stationnaire après une première différenciation, on peut en appliquer une seconde, notée \(\nabla^2 y_t\), et ainsi de suite jusqu’à obtenir la stabilité statistique.
Ainsi, un modèle ARIMA combine :
- AR(p), la dépendance aux valeurs passées (composante autorégressive) ;
- I(d), la différenciation d’ordre \(d\) pour stabiliser la série ;
- MA(q), la dépendance aux erreurs passées (composante de moyenne mobile).
Lien entre le modèle ARIMA et le modèle ARMA : une série est un modèle ARIMA(p,d,q) si et seulement si la différenciation d’ordre \(d\) est un modèle ARMA(p,q).
L’équation générale s’écrit donc comme suit :
$$\nabla^d y_t = \mu + \sum_{i=1}^{p} \phi_i \nabla^d y_{t-i} + \sum_{j=1}^{q} \theta_j \varepsilon_{t-j} + \varepsilon_t$$
où :
- \(d\) correspond au nombre de différenciations appliquées pour rendre la série stationnaire ;
- \(\phi_i\) et \(\theta_j\) ont le même rôle que dans les modèles ARMA, respectivement les coefficients autorégressif et de moyenne mobile ;
- \(\varepsilon_t\) désigne l’erreur résiduelle, représentant la part aléatoire non expliquée par le modèle.
Par exemple, pour un modèle ARIMA(2,1,2) :
- l’ordre \(p = 2\) signifie qu’on tient compte des deux valeurs précédentes \(y_{t-1}\) et \(y_{t-1}\) ;
- \(d = 1\) indique qu’une différenciation de premier ordre a été effectuée ;
- \(q = 2\) signifie que l’effet de moyenne mobile est basé sur les deux erreurs précédentes.
L’équation devient :
$$\nabla y_t = \mu + \phi_1(\nabla y_{t-1} – \mu) + \phi_2(\nabla y_{t-2} – \mu) + \varepsilon_t + \theta_1\varepsilon_{t-1} + \theta_2\varepsilon_{t-2}$$
Autrement dit, la variation actuelle dépend à la fois des variations précédentes (mémoire temporelle) et du choc aléatoire précédent (effet correctif), tout en tenant compte de la stationnarité par la différenciation.
Les graphiques ![]() suivants illustrent l’évolution d’une série ARIMA(2,1,2) et de son ACF.
suivants illustrent l’évolution d’une série ARIMA(2,1,2) et de son ACF.
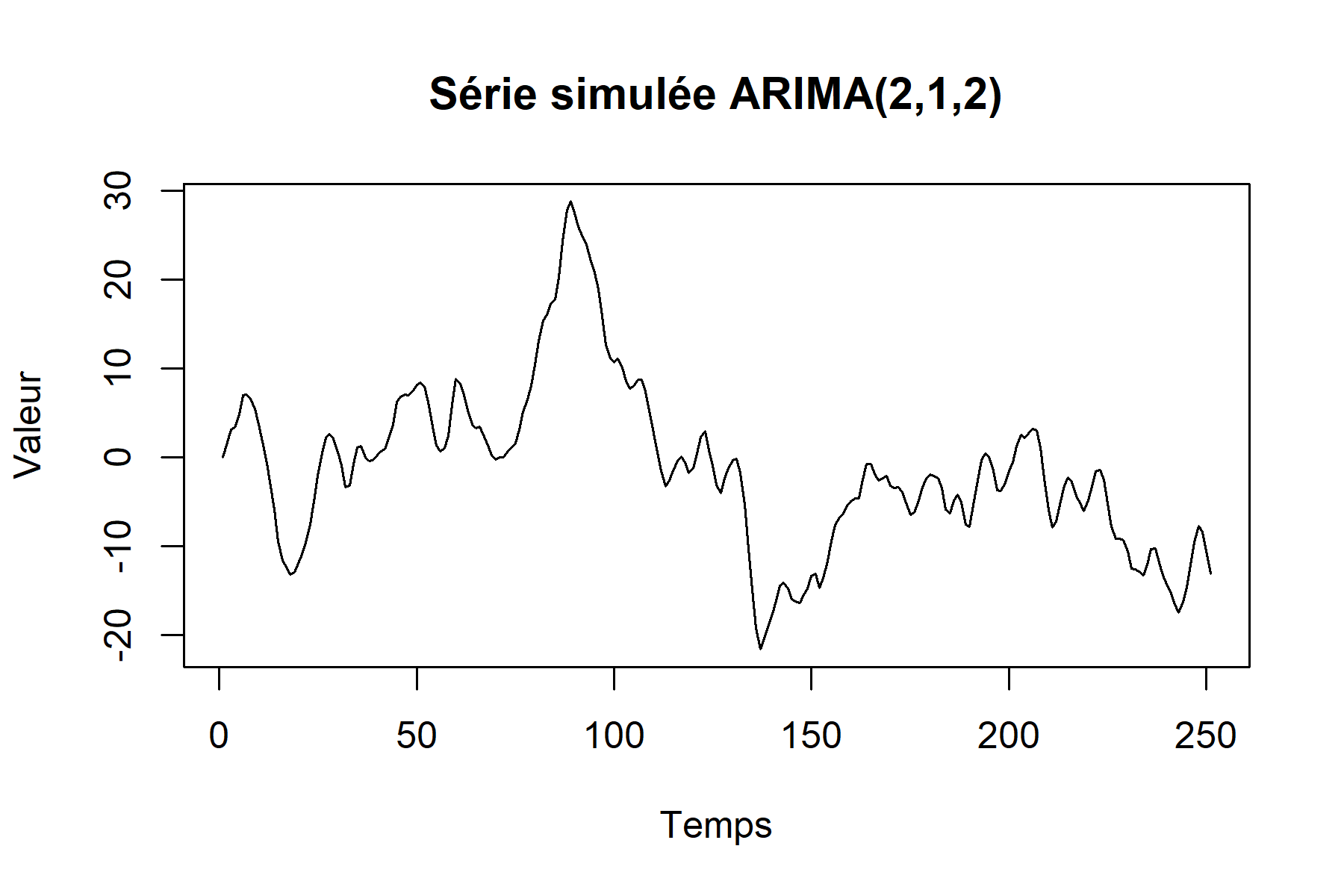
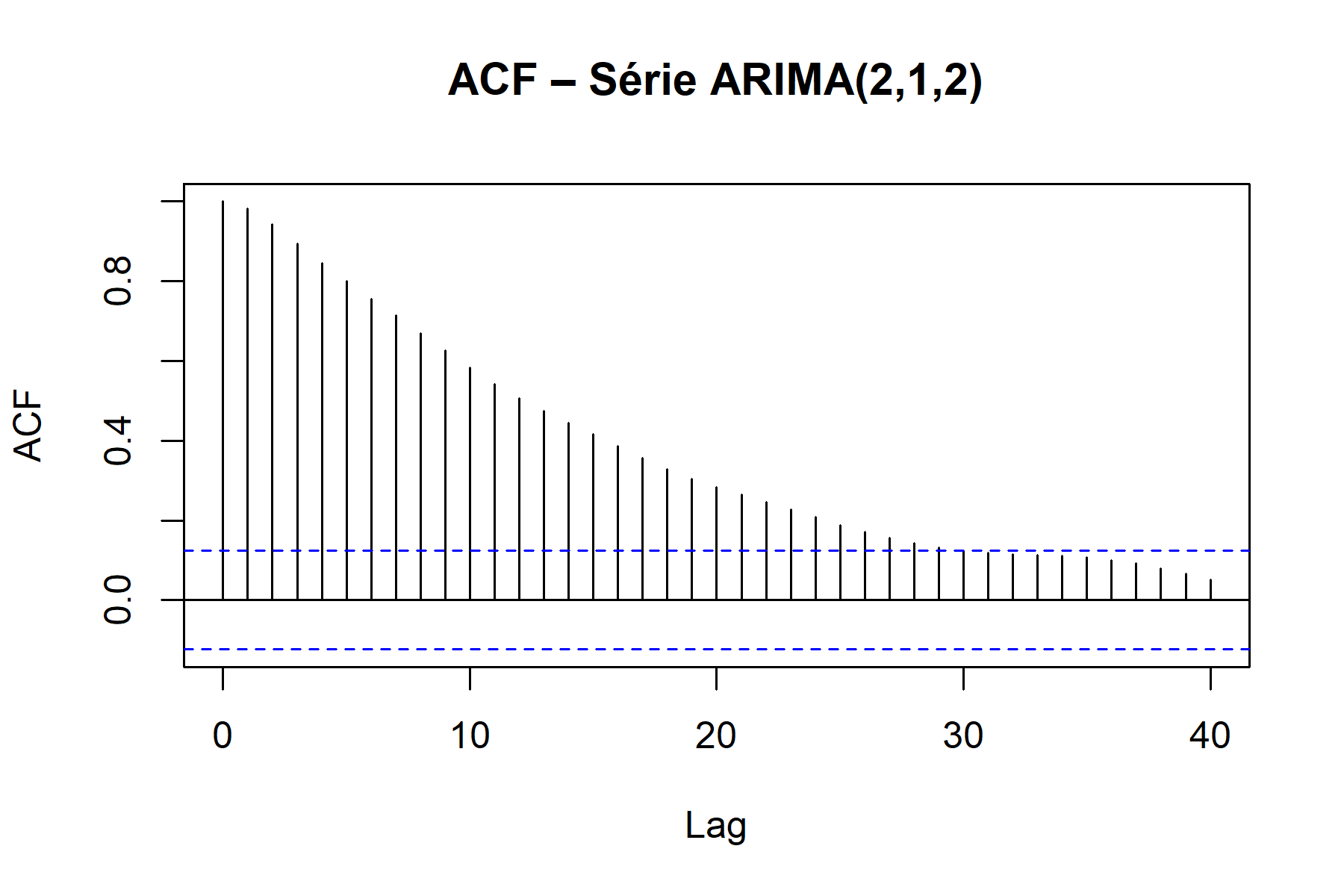
La série montre une tendance ascendante avec des fluctuations autour de cette progression. Elle illustre comment un modèle ARIMA combine mémoire du passé et corrections successives pour décrire une évolution non stationnaire. L’ACF décroît lentement, signe que les valeurs restent liées sur plusieurs périodes : un comportement typique des séries non stationnaires nécessitant une différenciation.